We are excited to see Aave expand to zkEVM! In this post, we provide rationale for why the Aave community should use the Pyth oracle to provide reliable, robust, and scalable price feeds for consumption by the protocol and its users in this new deployment.
About Pyth
The Pyth network is an oracle provider that makes financial market data available to multiple blockchains. Pyth’s market data is sourced from 80 first-party data providers, including some of the largest exchanges and market making firms in the world. The oracle offers currently offers 200+ price feeds for a number of different asset classes, including US equities, commodities, FX, and cryptocurrencies.
The oracle’s price feeds are designed to be fast, accurate, and reliable. Price feeds update multiple times per second—you can see live price updates on the Pyth website. Each price update is a robust aggregate of multiple data providers’ reported prices. The oracle uses an aggregation procedure to ensure that colluding (or accidentally incorrect) providers cannot substantially influence the aggregate price. Feeds are also reliable due to the redundancy between providers.
To date (launch in mid December 2022), the Pyth on-demand model has already delivered close to 700K price updates on-chain—with an ATH of 25K on-chain price updates in a single day following the launch of 22 perpetual markets on Synthetix Perps and the USDC depeg.
How does Pyth work?
Pyth runs aggregation for its Pythnet Price Feeds on its own application-specific blockchain called Pythnet a proof-of-authority chain, where the data providers run the validators for the network. Prices are delivered to other blockchains via the Wormhole interoperability protocol and a permissionless on-demand price update model. Pythnet is a computation substrate to securely combine the data providers’ prices into a single aggregate price for each Pyth price feed. Pythnet forms the core of Pyth’s cross-chain price feeds that serve all blockchains.
Pythnet Price Feeds Workflow
When a user (application, end user, liquidator, anyone…) wants to use a Pyth price in a transaction, they retrieve the latest update message (a signed VAA) from the price service and submit it in their transaction. The Pyth Data Association provides a public price service that allows anyone to listen for these messages via an HTTP or Websocket API—the network strongly recommends any application using Pyth in production environments to run its own price service instance for maximum reliability and decentralization. Finally, the target chain Pyth contract will verify the validity of the price update message and, if it is valid, store the new price in its on-chain storage.
The Pyth on-demand model is already available on 15 different blockchains and leading DeFi apps like Synthetix (Optimism), Ribbon Finance (Ethereum), CAP Finance (Arbitrum), or Aurigami (Aurora) have since integrated with Pyth’s innovative model. Pyth design enables anyone to access the full suite of Pyth price feeds, regardless of the blockchain you are on. Thus, whether your application is on Ethereum or any of its L2s, it will have access—at will—to the 200+ and growing Pyth price feeds. Pyth Network already has its contract deployed on Polygon zkEVM from which any on-chain application can read the current value of any price feed and onto which any user can pull the up-to-date Pythnet price.
Pyth already supports the assets mentioned in this temperature check (ETH, MATIC and USDC). In regards to the greater AAVE ecosystem, most of the assets accepted by Aave including but not limited to ETH, USDT, USDC, DAI, cbETH, CRV, LINK, BTC, AVAX, MATIC are also supported by Pyth. Pyth price feeds for rETH, stETH, BAL and FRAX are currently in progress of being listed, and if this proposal were to pass, the network would work toward adding any missing price feeds to further support Aave.
Robust and Decentralized
As mentioned above, the Pyth Network boasts 80 leading data providers spanning the largest crypto exchanges and leading market making firms including names like Wintermute, Jane Street, Binance, OKX and many more. Each data publisher streams first-party data on-chain to Pyth for subsequent aggregation and output.
Data publishers risk critical reputational and economic consequences should they attempt to act maliciously. Furthermore, individual data publishers have minimal incentive to do so as Pyth’s conservative minimum publisher thresholds and robust aggregation logic prevent any single data provider from materially influencing the Pyth price for their own economic gain. That is, if publishers are submitting a price of $100 and one publisher submits a price of $80, the aggregate price should remain near $100 and not be overly influenced by the single outlying price.
Scenarios for the aggregation procedure. The lower thin bars represent the prices and confidence intervals of each publisher, and the bold red bar represents where we intuitively would like the aggregate price and confidence to be.
Pyth can attribute this robustness to its simple yet comprehensive two-step aggregation algorithm. In the first step, data publishers provide three votes on the price of the asset — one vote at their price and one vote at each of end (+/-) of their confidence interval — following which Pyth simply calculates the median of all the votes. The second step computes distance from the aggregate price to the 25th and 75th percentiles of the votes, then selects the larger of the two as the aggregate confidence interval.
This process acts like a hybrid between a mean and a median, giving confident publishers more influence, while still capping the maximum influence of any single publisher. The algorithm has an interpretation as computing the minimum of an objective function that penalizes the aggregate price from deviating too far from the publishers’ prices. This interpretation allows us to prove properties of the algorithm’s behavior: for example, the aggregate price will always lie between the 25th and 75th percentiles of the publishers’ votes.
In addition to robustness, Pyth has high uptime. For example, defining downtime as a period in which the most recent Pyth update was at least 5 slots (~2 secs) old, Pyth had 99.97% uptime for ETH/USD over the one-week period of March 28, 2023 through April 4, 2023. When that definition is altered to allow a max staleness of 10 slots (~4 secs), Pyth had 100% uptime for that feed over that period.
Pyth Performance
To assess the potential benefits of this proposal, we evaluate Pyth between March 28, 2023 00:00:00 and April 4, 2023 00:00:00 PM (both UTC) on its AAVE/USD and ETH/USD price feeds. We constructed a price series for the replicator (option 1) by using the Chainlink prices that would be bridged from Ethereum and API3 (option 3). Note: For API3, we use the AAVE/USD feed and the ETH/USD feed on zkEVM. For the centralized exchange (CEX) reference point for prices to evaluate the accuracy and latency of the oracles’ prices, we use Binance’s extremely liquid AAVE/USDT and ETH/USDT price feeds.
During this period, the Pythnet feed updated and sent out a Wormhole VAA 586,975 times (on average once every 1.03 seconds). In comparison, during this period Chainlink updated 186 times and API3 updated 50 times.
To showcase Pyth’s performance, we plot the Pyth, Chainlink, API3, and CEX prices for AAVE/USD. We show below a zoomed-in version of the price plots for the smaller period March 28, 2023 09:00:00 to March 28, 2023 20:00:00, to better visualize the differences in the price series. The plots show that the oracle price feeds generally follow the CEX price feed with a bit of lag—as can be seen in the instances where the CEX price slightly precedes the oracle price. As can be seen, the Chainlink feed updates more frequently (12 updates) and tracks the CEX price better than API3 (6 updates), though it is still low frequency and has high tracking error relative to Pyth.
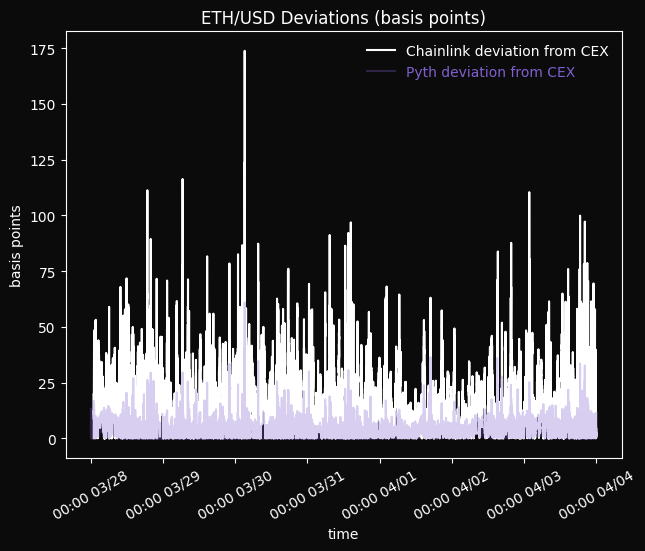
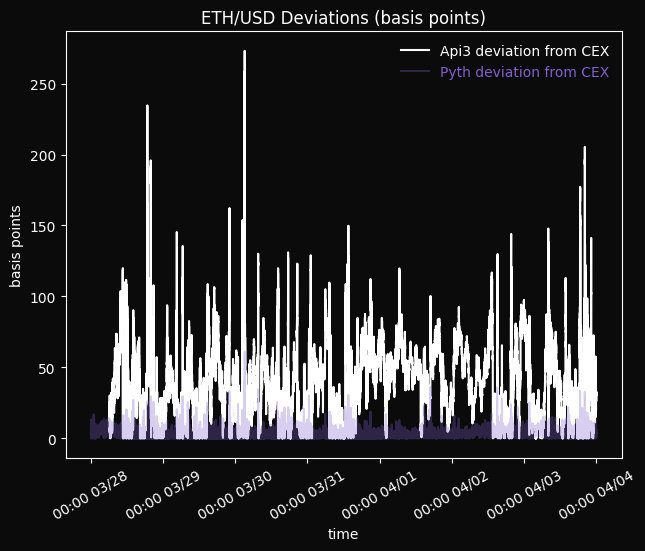
The following charts show the deviations for the full time period between the Pyth Network price and the CEX price and between the CEX price and each of the prices of Chainlink and API3, expressed in basis points (1 basis point is 1/100th of 1 percent). These plots show that the deviations of Chainlink from the CEX are significantly higher than those of Pyth, and that API3 has the highest deviations of all.
Another way to visualize this is via the plot below, which showcases the distribution of Pyth deviations from CEX and each of the distributions of the other oracles’ deviations from CEX in the form of a CDF. When comparing two CDF curves, the curve to the left is better, indicating lower tracking error. As can be seen, the Pyth CDF is generally to the left of all other curves. Note that the x-axis is on a log scale. Thus, a difference of 1 tick represents an improvement by a factor of 10. The charts below show that Pyth typically outperforms the other oracles by a factor of at least 10x.
The following table reads off the deviations at various percentiles from the above charts:
During this period, the Pythnet feed updated and sent out a Wormhole VAA 587,225 times (on average once every 1.03 seconds). In comparison, during this period Chainlink updated 274 times and API3 updated 29 times.
Similar to above, the price plots are for the subperiod March 28, 2023 06:00:00 to March 28, 2023 12:00:00. They show that the Chainlink feed updates more frequently (12 times) than API3 (3 times), though it is still worse than Pyth.
The deviation plots below corroborate this:
The charts below show that Pyth typically outperforms the other oracles by a factor of around 10x for ETH/USD.
The following table reads off the deviations at various percentiles from the above charts:
We can estimate the latency of Pyth prices relative to the CEX by taking the deltas of the price feed (i.e. p_{t+1} - p_t) at the price service level and checking the correlation of the oracle deltas with the CEX deltas at different lags. The lag at which we observe the optimal correlation is one way of estimating the latency introduced by the oracle itself. We can do a similar calculation for the other oracles as well. The table below shows the observed latency for the different oracles on the two feeds over the weeklong period of relevance.
As can be seen, Pyth has a relatively low latency (which matches the much lower deviations it observes relative to CEX than Chainlink or API3). Both Chainlink and API3 have relatively long lags in producing prices that can be consumed, which corresponds to the higher deviations relative to CEX price. These latency numbers help to explain the order-of-magnitude difference we see in the deviations of the oracles from the CEX price.
Implementation
The first step to this will be a snapshot vote for the Aave community to determine deployment on zkEVM using Pyth’s Pythnet Price Feeds.
Integrating with Pyth Network on zkEVM is straightforward, though slightly different from other oracles. The integration work is analogous to what is outlined in the Synthetix SIP about using Pyth prices:
Integrating with Pyth Network has two steps:
- The on-chain contract reads prices from the Pyth Network contract.
- Any application that sends transactions to the on-chain contract—e.g., a web frontend—needs to simultaneously send a Pyth price update. This update can be retrieved from the Pyth Network price service (which simply relays it from Wormhole’s peer-to-peer network).
The Pyth Network SDKs help integrators with both of these steps. An example frontend and contract integration is shown here in the javascript SDK.
The changes are simple to make, and as soon as Pythnet price feeds are integrated into the protocol pricing logic, Aave v3 can be deployed on zkEVM.
Conclusion
Choosing an oracle for a new deployment requires careful thought around several considerations like accuracy and robustness. We recommend that the Aave community choose Pyth for its oracle on zkEVM for the following reasons:
-
Quality—Pyth provides accurate and frequently updated prices that track price movements on primary trading venues closely. This allows protocols to both remain safe and offer good prices to their consumers.
-
Readiness— Pyth is already live, and anyone on zkEVM can already access Pythnet price feeds on the L2.
-
Reliability—Segmenting reliability into availability and accuracy, Pyth does well in both categories. Pyth provides accurate prices with very little downtime.
-
Security—Pyth is a truly decentralized oracle, with robustness guarantees in the form of its set of highly reputable data publishers, aggregation algorithm’s properties, and the confidence interval. Pyth’s publishing workflow includes multiple parties at each part of the stack, which means there is no single point of failure. By contrast, using the replicator mechanism is dangerous because it is dependent on a single operator remaining live.
-
Asset coverage—Unlike other oracle services, once a new price feed is requested on one chain and is made available via Pyth, it instantly becomes available on all Pyth-supported chains. The Pyth model’s scalability means asset coverage is high from day one and grows continually as new symbols are added for any use case on any chain.